MaiBot程序配置指南
---Powered by ARC
本文档详细描述了Windows一键包的部署流程
版本限制:0.11.6及以上,各版本通用(12月5日)(一键包可通过Q群内获取)
由于本文档内容较长,请务必详细阅读!如果你知道你的目的,请点击右侧列表中对应标题以快速跳转
📝 部署前声明:
- 文档内一共包含三种颜色的文字:
- 黑色: 按照流程阅读并进行操作的部分。
- 蓝色: 如果你能看得懂对应内容,可以参照执行,此部分用于讲解部分原理以及诱因。
- 红色: 重要警告或高风险配置项,修改前请务必确认自己知道在做什么。
如果按照本文档进行逐步部署,理论上不会出现问题
如有问题,请先结合文档查看你的流程是否出现了问题;如果你自己很确信流程没有问题,且已经结合文档核对相关操作了,在群内提问即可:
但烦请务必附上包含完整内容的截图以及详细的问题描述,包括但不限于出现问题时进行到的步骤,窗口的情况以及其窗口内部的完整内容等,否则将无法辅助排查问题!
部署前请保证阅读以上须知内容!
注意!关于本文档内红字标明谨慎修改的内容,尽可能不要修改,以避免造成意料之外的错误
承接一键包的指南来继续展开:
(docker/linux的基础逻辑与此相同,除部分文件位置不同)
我们上文在一键包部署指南中有提到 “MaiBot主程序”(下文简称为core),“Napcat-adapter”(下文简称为adapter)以及“Napcat”,这三个模块共同构成了MaiBot整体,缺一不可 其中:core可调整的配置项有“bot_config.toml”,”model_config.toml”,adapter可调整的配置项有”config.toml
以上配置文件均可通过主程序-WebUI管理或文本编辑器进行手动修改,但Napcat只能通过Napcat-WebUI进行管理!
首先,我们需要了解可以而且需要调整的配置项
在这里,我们首先讲解如何通过WebUI对应修改配置文件
⚠️ 请注意!通过一键脚本启动的MaiBot应为目前git仓库的标准发行版本,图片样式可能与文档中有所区别,但是修改的位置以及内容理论上不会有大改动,如有改动请@ARC更新文档支持
⚙️ 麦麦主程序配置
这里先讲解通过可视化WebUI进行配置的基本修改,修改时,请结合本文档以及WebUI页面实际显示进行修改(请注意!只有标注可修改的内容才可修改!) 以下所有提到的修改均可在官方文档内了解详细信息 模型配置指南
🧩 基本信息
可修改: QQ账号,昵称,其他平台账号,别名
QQ账号: 麦麦bot的QQ账号 昵称: 麦麦bot的名字
如果你开启提及回复的话,修改此字段,可在叫别名的时候成功让bot回应你
其他平台账号: 无多平台需求则无需修改
如有,按照”wx:123123123”或者”qq:123123123”的方式填写账号
别名: 麦麦bot的小名,或者乳名
如果你开启提及回复的话,修改此字段,可在叫别名的时候成功让bot回应你
🧬 人格
可修改:人格特质,表达风格,兴趣,说话规则与行为风格,私聊规则, 识图规则,状态列表,状态替换概率
人格特质: 麦麦bot的简短人设,请尽可能用简短扼要的关键词来描述麦麦的人设,可涵盖人格特质和身份特征即可
表达风格: 麦麦bot说话的风格,此项会影响它生成回复时的语气和用词
兴趣: 描述麦麦bot感兴趣的话题/领域,当群内聊到对应话题时,麦麦会更加愿意参与回复
说话规则与行为风格: 用于控制麦麦在群聊中的发言习惯 以及调用工具的主动性(可与插件搭配使用)。
⚠️ 建议保留默认的前三条规则不动。
如需自定义,请 从第 4 条开始按序号逐条添加,避免打乱默认逻辑。
私聊规则: 调整麦麦bot在私聊内的发言风格 以及调用工具的主动性(可与插件配合使用)
⚠️ 建议保留默认的前三条规则不动。
如需自定义,请 从第 4 条开始按序号逐条添加,避免打乱默认逻辑。
识图规则: 如果无必要,不要修改此段落,除非你知道你在做什么!
状态列表: 麦麦聊天时的人格变化,配合状态替换概率,可用于回复风格调整 你可以通过添加状态,并按照示例状态进行自定义
状态替换概率: 根据状态列表进行人格随机替换的概率,概率越高,越容易切换
💬 聊天
可修改:聊天频率,上下文长度,规划器平滑,将planner推理加入replyer,动态发言频率
聊天频率:取值在0~1之间,频率越低,越沉默;反之越活跃
上下文长度: 麦麦在回复时所看到的上文的数量(如果不了解相关机理,请不要修改)
越大,信息越多,越全面,token越高;越低,信息越少,越专注,token越低
规划器平滑: 如果无必要,不要修改此段落,除非你知道你在做什么!
值越大,planner 被调用的间隔越长,负载更低,但整体反应速度会更慢一些;0 表示关闭这个平滑机制,让聊天循环尽可能快速进行
将planner推理加入replyer: 如果无必要,不要修改此段落,除非你知道你在做什么!
如开启此项,决策模型的生成内容将填入回复模型的上下文中,可以加强麦麦对于文段的理解能力,缺点是提高token的消耗(以及极端情况下的答非所问)
动态发言频率: 此项用于针对性调整特定群聊/特定时间段的发言频率; 如果启动此项设置,将优先执行动态发言频率; 匹配时优先匹配详细规则,再匹配全局规则。
🗣️ 表达
可修改项:详见主程序-WebUI 表达方式:麦麦可以定期学习群内群U的聊天方式,通过分析,推测,模仿群友的句式,从而让麦麦更像人 表达共享组配置:通过设置表达共享组,不同群的表达方式可以互通,并互相学习(注意:只有表达方式受影响,记忆不受影响)
🛠️ 功能
可修改项:工具设置,记忆设置,表情包设置,达到最大数量时替换表情包,偷取表情包,启用表情包过滤
工具系统: 允许麦麦调用包括lpmm知识库在内的工具以及所有“外置”的插件,如不了解请不要关闭!
记忆设置: 记忆思考深度:允许麦麦在发言之前进行思考斟酌,思考深度越高,回复越有意义,消耗的Token越多,用时越长
表情包设置:
激活频率:麦麦发送表情包的概率(只计算在麦麦准备回复时额外发送表情包的概率)
最大注册数量:麦麦所拥有的真正可用的而且可以发送的表情包数量
检查间隔:控制麦麦添加/检查/删除自己目前的表情包的频率,越低进行越频繁
启用表情包过滤:勾选此项后,麦麦只对符合要求的表情包进行添加注册
🧹 处理
可修改项:关键词反应配置,回复后处理配置。这里不做赘述,有需要自行检查调整配置即可
😶 情绪
可修改项:情绪设置 情绪系统:调整麦麦当前的心情以及情绪
注意!此项开启后,你的麦麦将不再受人设等提示词强约束,如需保持人设稳定,请不要开启此项!除非你真的把麦麦当做一个独立的个体!
🎙️ 语音
可修改项:语音识别 语音识别:调整麦麦是否能从发送的语音中提取出文字( 默认模型需要硅基流动密钥)
📚 知识库
可修改项:LPMM知识库
请注意!此部分较为复杂!请先阅读官方文档关于LPMM知识库的所有介绍,再自行尝试打开/调试/添加!
📄 麦麦知识库(新版LPMM)使用说明 | MaiBot 文档中心
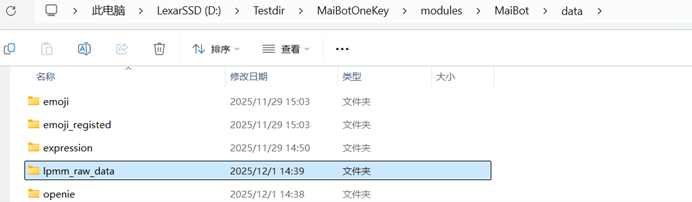
关于学习功能:你可以通过控制台CMD中“麦麦一键学习”选项来进行LPMM的学习,运行脚本后,在进行确认导入之前,你可以发现modules/MaiBot/data下新增lpmm_raw_data文件夹,将你的txt文件放进文件夹下,然后按流程按y即可如需删除知识库,直接删除rag和embedding文件夹即可
再次注意!如果没有必要,务必不要更改默认的嵌入模型,除非你知道你在做什么!!!
🗂️ 其他
可修改项:按需修改 此处的所有修改项对程序无明显影响,如果你知道你在修改什么,可以修改
🔌 麦麦适配器设置
如果你使用的是0.11.6版本及以上的WebUI,请参考此图:
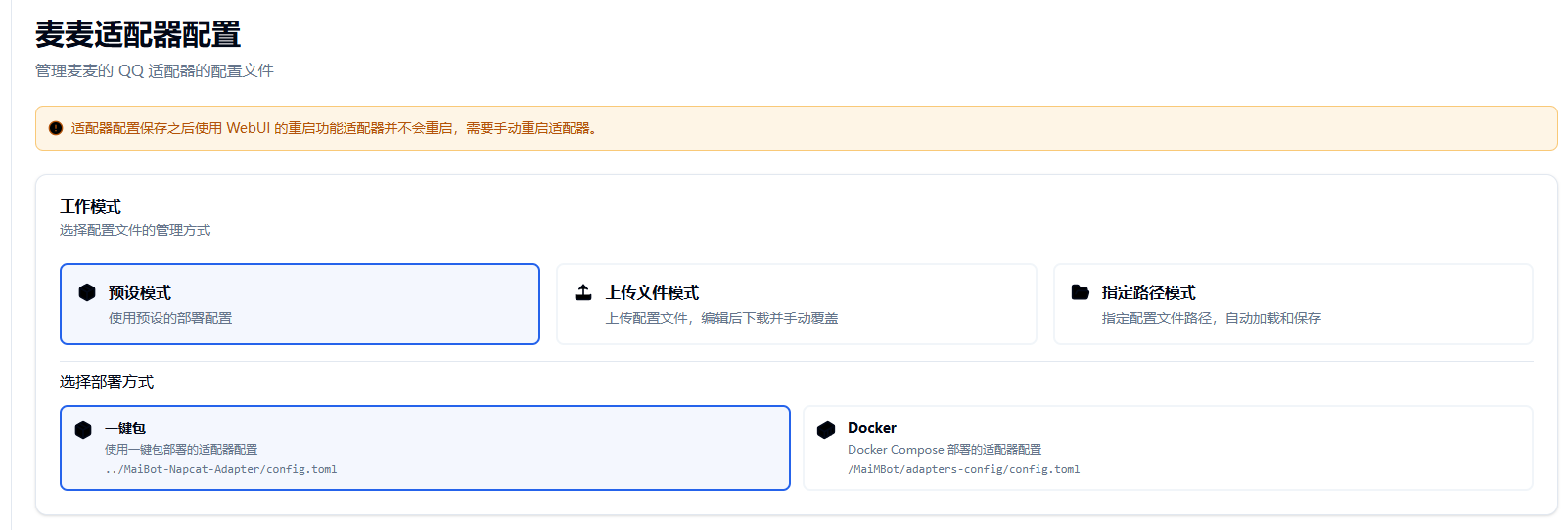 WebUI编辑适配器有三种方式:预设模式,上传文件模式,指定路径模式
WebUI编辑适配器有三种方式:预设模式,上传文件模式,指定路径模式
关于预设模式:目前支持一键包以及Docker部署,对应修改即可
关于指定路径模式:通过键入绝对路径,可直接加载对应位置的config.toml
关于上传文件模式:此功能仅适用于你知道文件的位置,但是不会手动修改的情况
如果你使用的是一键包,而且想直接编辑对应文件(不使用WebUI的话)你可以在截图位置找到名为config.toml的文档
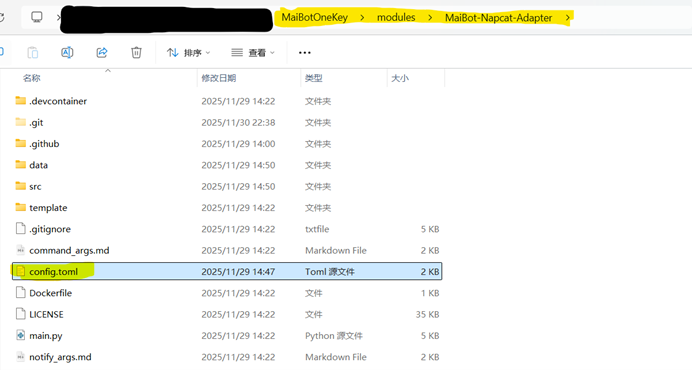
使用任何可用的文本编辑器打开,你会看到如下格式
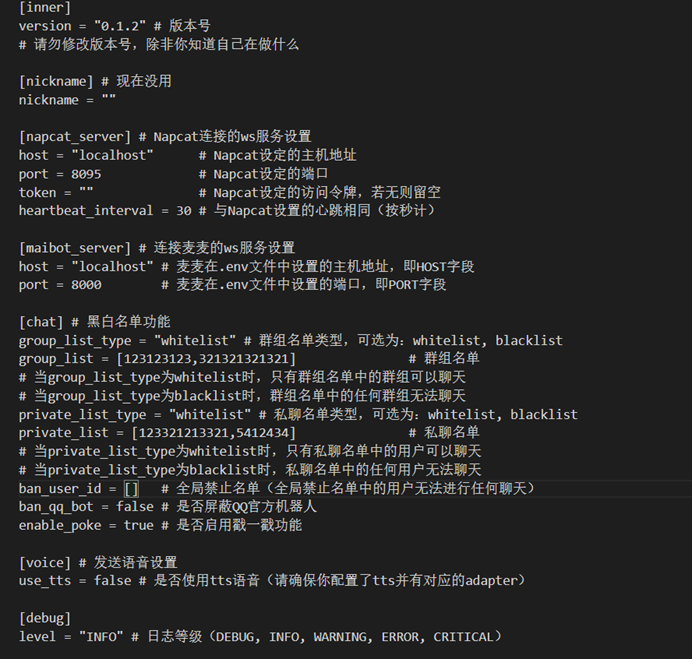
可修改项有:主机地址、端口、访问令牌、心跳间隔、WebSocket访问主机地址/端口、聊天黑白名单功能、发送语音设置、调试
主机地址/端口:此项用于调整adapter自身的Websocket客户端,Windows/linux环境下保留localhost即可,docker环境下应为0.0.0.0,如果没有特定需求,不要更改端口!
访问令牌:此项用于控制与Napcat之间的安全链接,如填写此项,需要在Napcat-网络配置保证访问令牌的一致性!
心跳间隔:如果没有特定需求,不要修改此项目!
关于群聊白名单/黑名单,白名单是只有列表上的群聊被回复,黑名单反之
关于私聊白名单/黑名单,白名单是只有列表上的私聊被回复,黑名单反之
关于群聊/私聊/黑名单列表的数组配置,如果直接编辑config.toml文件,必须按照[数字,数字,数字]之类的方式进行编写
不要使用中文逗号以及中文引号!如 “”;“,”
发送语音设置:此选项只有在你配置好文本转语音功能后才可启用!你可以通过插件/adapter等方式实现
调试:此部分根据个人需求按需调整即可!
🧠 AI模型厂商配置
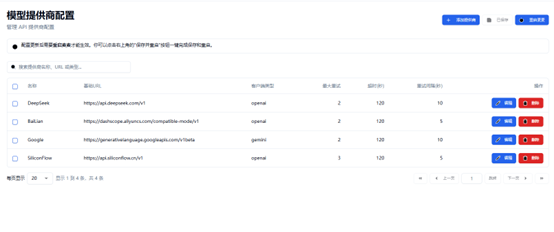
模型厂商:为麦麦提供大脑的来源,不可或缺
此页面囊括了四个常见的模型提供商,分别为DeepSeek、阿里云百炼、谷歌和硅基流动,其中,硅基流动作为新人第一次配置的平台而言最为友善。链接:硅基流动官网
点击链接并完成注册后会跳转到图片内页面,点击左下角”API密钥”
点击新建密钥
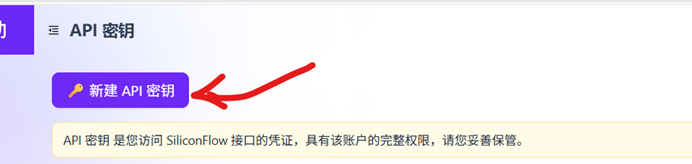
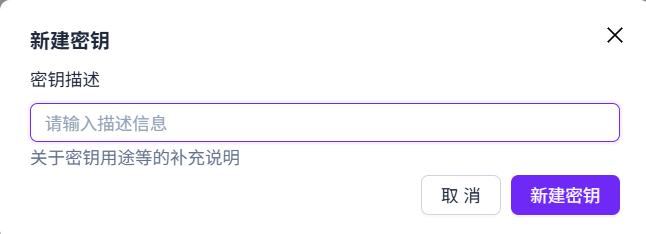
输入密钥信息
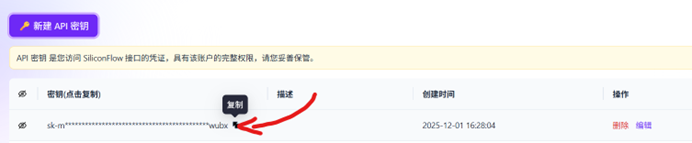
之后你会跳转到下方的页面,将鼠标悬停到页面左侧的字符串,点击复制(我们称之为API密钥)
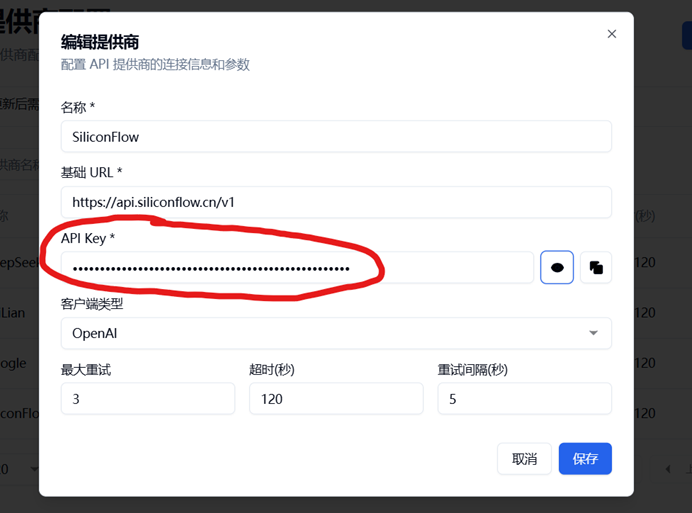
回到主程序页面,点击编辑
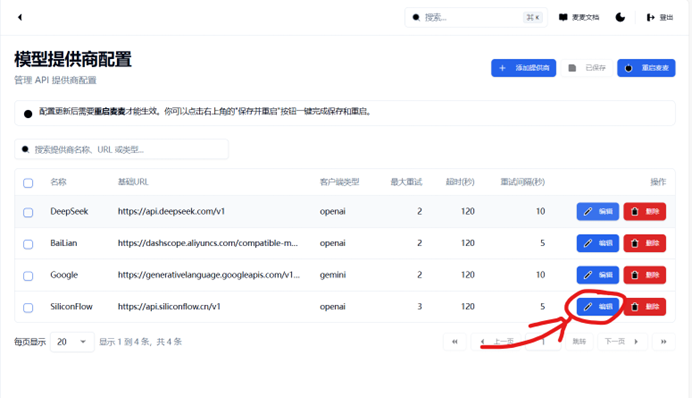
将获得的API密钥粘贴到主程序-WebUI的API KEY处,点击保存
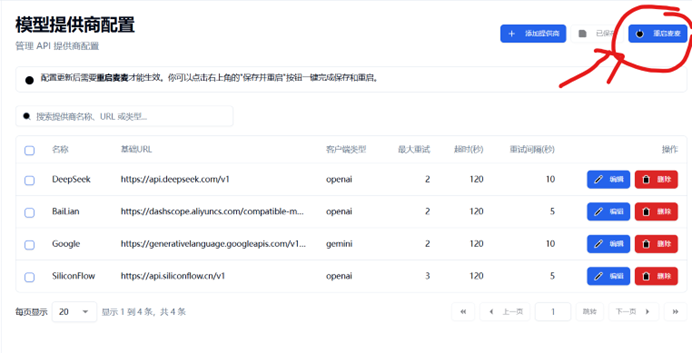
完成保存后点击重启麦麦,理应上你的麦麦可以正常运作了!
🌐 部分常见的大模型网站
(这里只收录有正规营业证明且有企业背书的平台)
Moonshot AI 开放平台 - Kimi 大模型 API 服务
🏗️ 如何添加模型供应商?
此配置流程根据模型供应商的不同而不同,在这里只描述常见流程:
首先,需要登录模型供应商平台,通过查看模型供应商的文档中心来获取API端点地址,如:
https://template.com/v1(这里仅做展示,无任何实际作用)并访问其个人中心,生成并获取API密钥,最后将获取到的端点地址和API密钥填入上文的基础URL以及APIkey即可
🧩 麦麦模型管理与分配
在我们开始介绍之前,请详细阅读以下工作原理(白话文方式):
大模型服务由大模型提供商提供,麦麦通过调用大模型提供商的API,发送API KEY以及 请求的大模型型号来获取大模型服务
麦麦内部 有很多工作模块,不同模块所使用的 大模型型号可能不同, 来源厂商也可能不同,
在向大模型提供商请求服务之前,麦麦需要确定自己使用的: 模型型号,来源,以及将其应用的内部工作模块
我们接下来的教程主要针对模型型号,来源,内部工作模块进行详细讲解:
首先,让我们先借助WebUI讲解基础操作方式,再详细讲解如何配置添加模型 模型配置详情页
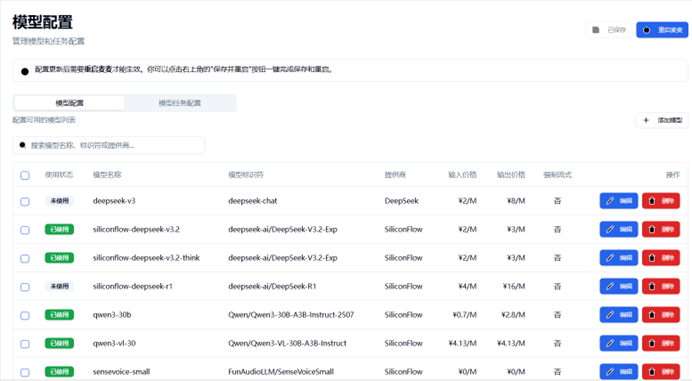
此页面包含你目前在配置文件写入的所有未使用/已使用的模型,其中: 左侧勾选框用来进行批量选择功能 右侧编辑按钮用来调整模型内部配置,删除按钮可删除对应模型
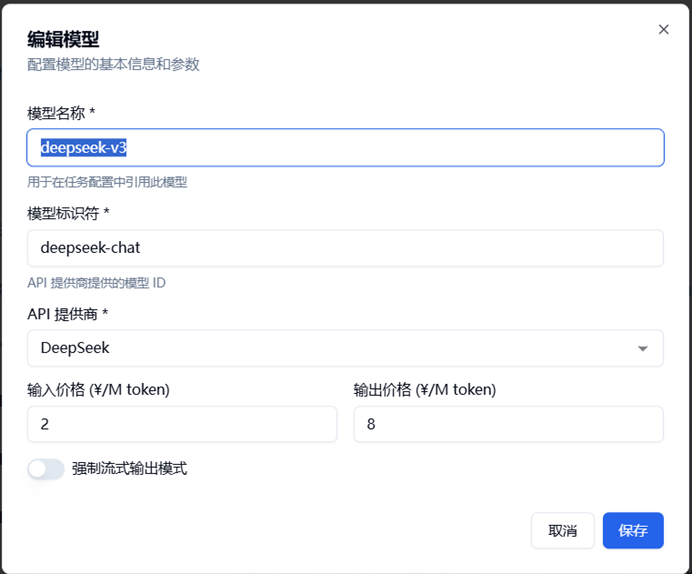
编辑模型页面中,包含可修改字段: 模型名称,模型标识符,API提供商,输入/输出价格
模型名称:此模型在麦麦主程序内所用来称呼的名称, 模型任务配置部分需要使用此字段
模型标识符:此模型在模型提供商处所对应引用的模型ID
API提供商:此模型的来源提供商
输入/输出价格:主程序用来计算金额消耗的单价,用于统计数据
强制流式输出模式:如果你不知道这个字段的作用,不要修改!
🧱 为模型分配功能详情页
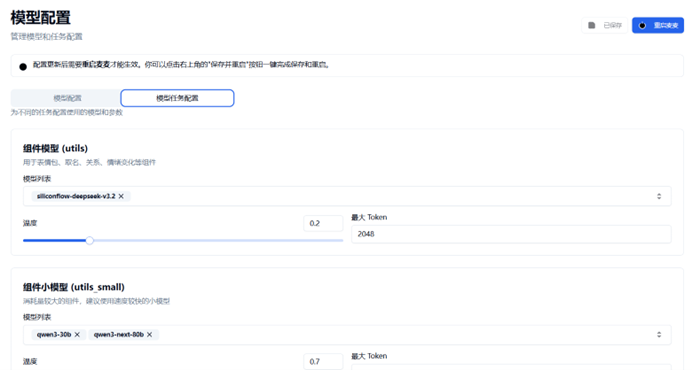
此页面用来分配麦麦各模块使用的模型
其中共有: 组件模型、组件小型号、工具调用模型、首要回复模型、决策模型、图像识别模型、语音识别模型、嵌入模型、实体提取模型、RDF 构建模型、问答模型
相关描述在WebUI内有详细注明,不再赘述
详细了解请参照官方文档
🧪 实际演练
为某组件添加模型
我们在此以硅基流动导入DeepSeekV3进行举例:
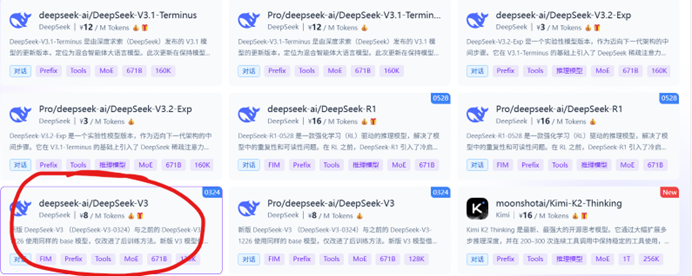
在这里,你可以看到琳琅满目的模型,其中,左下角是我们要添加的模型,点击左下角
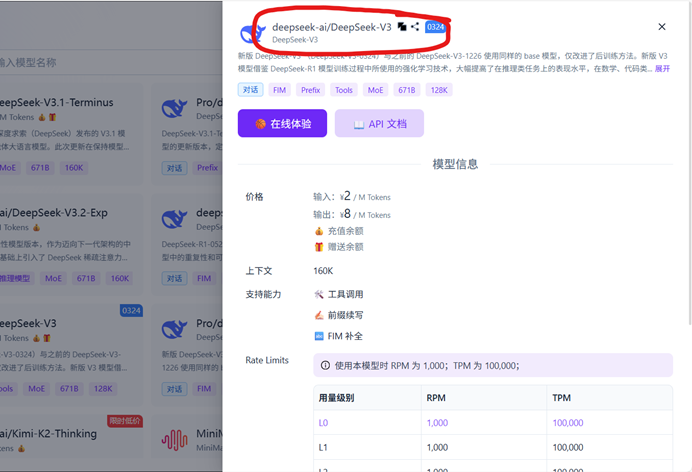
弹出模型的详细说明页,图片中红色圈的部分即 模型标识符,点击复制按钮,获取标识符
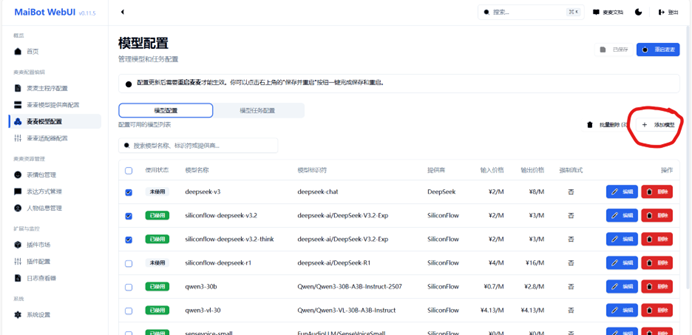
回到主程序-WebUI,点击红色圈中的“添加模型”,会弹出模型的详细配置页
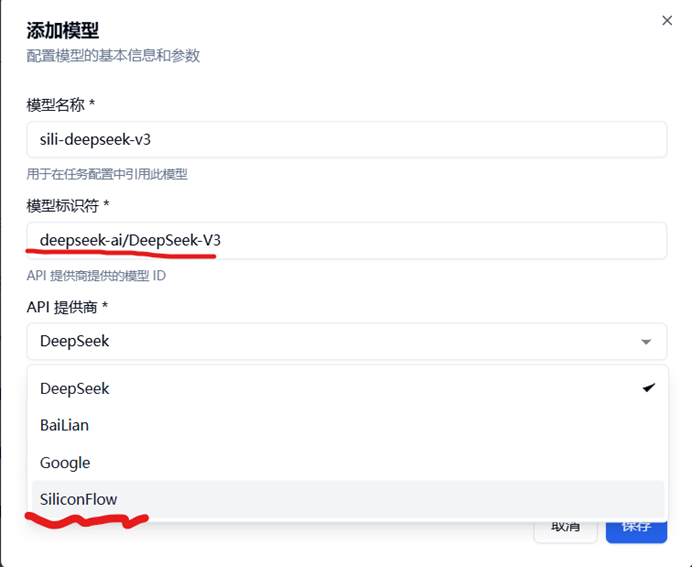
模型名称:按照个人想法填写即可, 建议合理填写以便于后续查找(图片中sili-deepseek-v3含义是硅基流动-deepseek-v3)
模型标识符:即我们 从硅基流动获取的模型ID,将其 原封不动复制进去即可
API提供商:即我们 获取模型ID的提供商,对应选择即可
输入/输出金额:按照模型提供商注明的金额填写即可
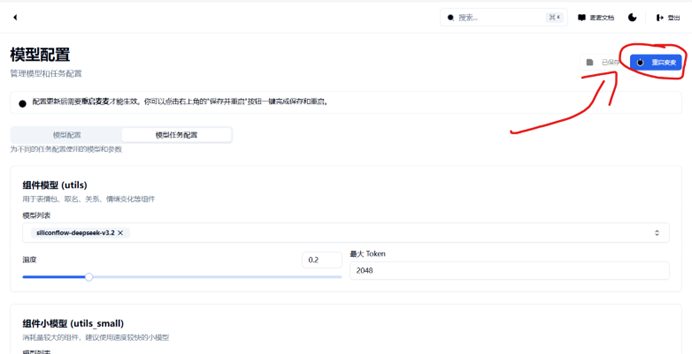
完成填写后点击保存,如果操作无误,你应该会在页面最下方看到你新建的模型
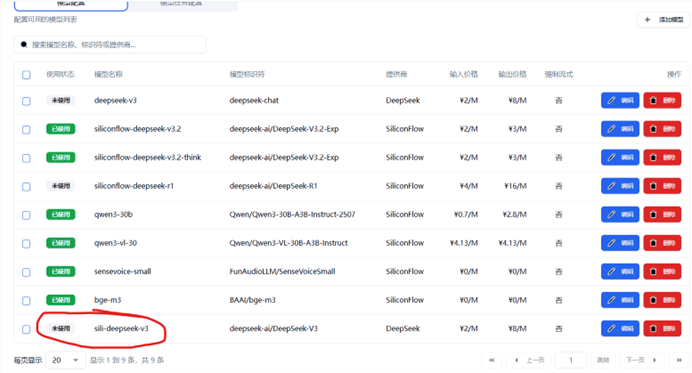
接下来,请记住你的模型名称,点击模型任务配置,我们在主回复模型处添加新模型:
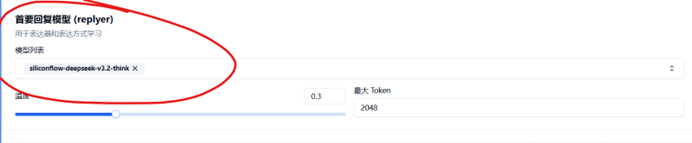
点击模型列表(空白处),你会发现跳出了子列表
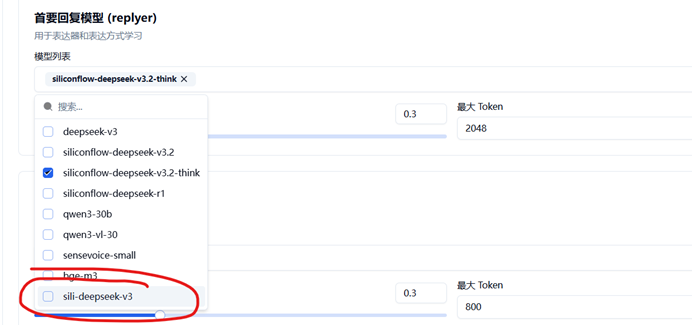
将我们新添加的模型勾选上即可, 或许你会注意到部分模型不在弹出的字列表上,对应删除掉即可

完成配置的话,应该会类似图片内的配置, 点击右上角重启麦麦即可
至此,恭喜你完成了模型的添加🎉🎉🎉
🎭 麦麦资源管理(表情包/表达方式/人物信息)
本部分粗略描述麦麦机器人的表情包/表达方式/人物信息管理器 理论上根据WebUI的配置介绍,本文档不需要进行讲解,故只附上截图
🔍 扩展与监控
0.11.6版本的WebUI已经加强对插件部分的技术支持,这里只提醒目前可能出现的问题:
0.11.4~0.11.5版本通过WebUI下载的所有插件均需要进行文件重命名,如图:
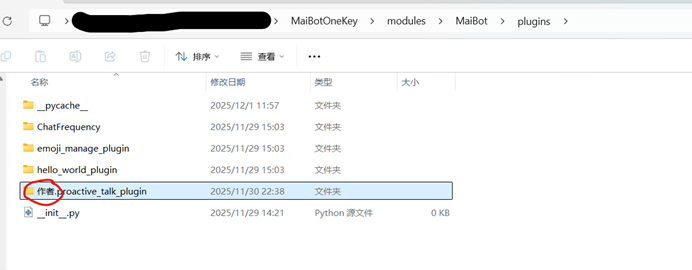
在指定路径下红色圈出的部分“ 作者.”必须删除并重启主程序才能识别到插件。详情插件使用文档请见插件市场Github作者的README文档以及官方文档 插件系统使用文档
😫我什么都不懂!我只想把麦麦跑起来!
按下面顺序做就够了(具体细节参照之前的章节):
- 确认你的主程序/adapter以及napcat成功启动(参考上一份《一键包部署指南》)
- 配置硅基流动模型厂商
- 确认你是否为群聊/私聊添加了白名单
- 保存你的配置修改项并重新启动主程序和adapter
- 在 QQ 群里 @麦麦,如果有回复,就是成功了!
❓ 还有问题?!
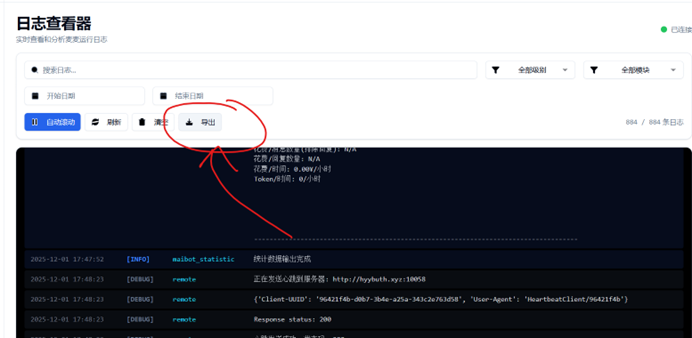
请根据图片内的指示,获取日志文档(命名为logs-YYYY-MM-DD-ABCDEF.txt),以及Napcat、adapter的控制台日志(如有必要) 并将其发送到群聊内,我们会尽可能解决你的问题!
如果你真的不知道什么是日志的话,把黑色窗口全都截屏下来,合并为一条聊天记录并进行转发,并听从他人的指示操作!